This is going to be a short post or rather a testlog for how to run the most accurate version of Microsoft Phi-4 on your Mac.
Step 1: Setup ollama
On a mac, you can install ollama using homebrew:
brew install ollamaOn a Windows/ Linux device, you can follow the instructions on the Ollama Docs)
Step 2: Kickstart ollama
ollama serveStep 3: Run inference with Phi-4
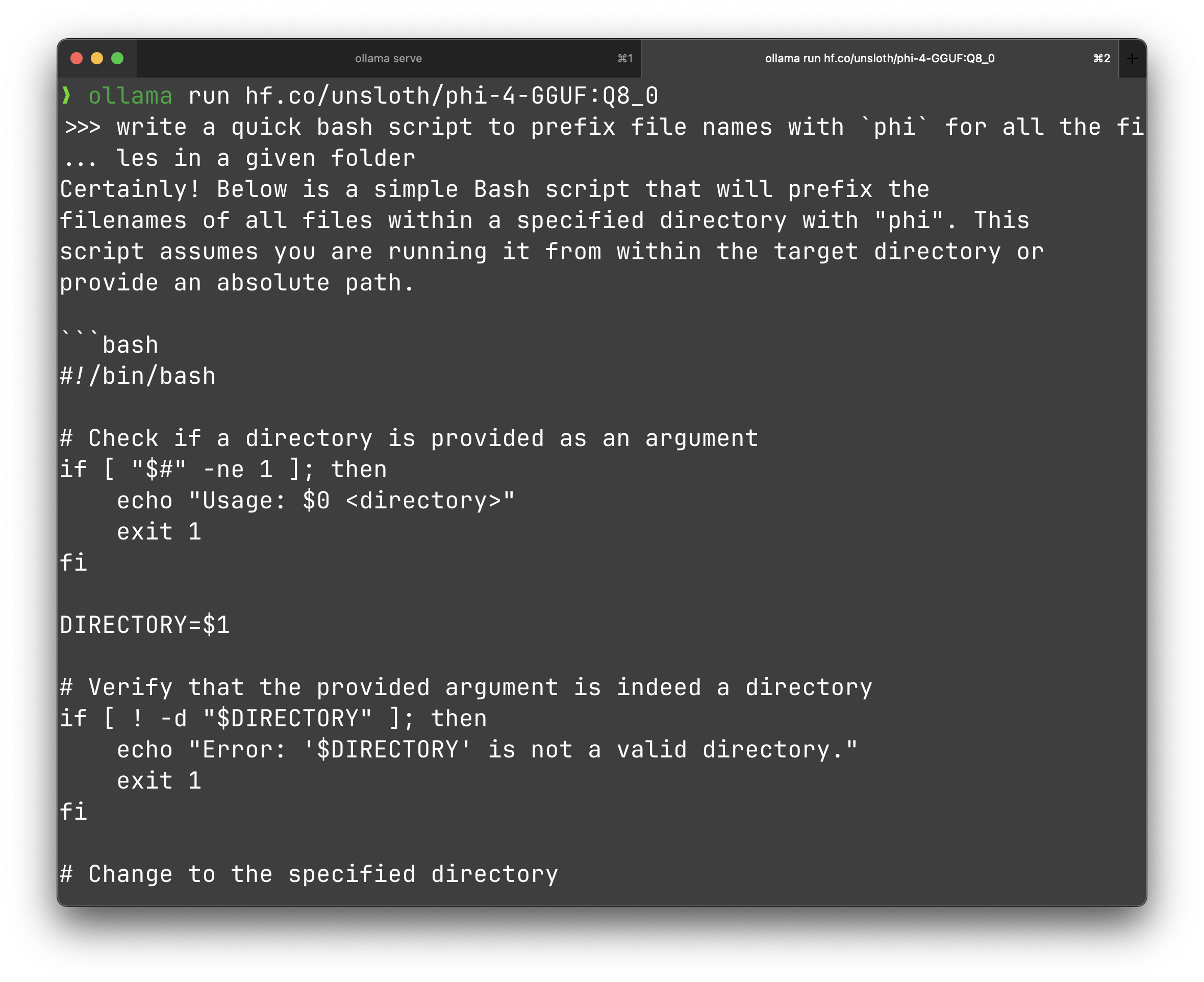
After some research I found that the Phi-4 GGUFs from Unsloth are the most accurate. They ran bunch of evals and also converted the model to LLaMa format. You can find it here: unsloth/phi-4-GGUF.
ollama run hf.co/unsloth/phi-4-GGUFI’d also recommend reading the blogpost about the fixes for the Phi-4 model here.
Step 4: Use it for your own tasks
That’s the fun bit, once the model is loaded, you can do whatever you want, at the touch of your terminal.
Go on and try out some of your own prompts, and see how it works.
Bonus: Now go try other GGUF models on the Hub and compare their performance with Phi 4.
and.. that’s it!
Oh, sorry, one last thing, you can now even run private GGUFs from the Hugging Face Hub via ollama, read here.